It's that time of year and I'm writing reports again. It shows that Greig has left, the number of blog entries has dramatically since the end of March... yes, I am still trying to persuade the rest of the group to blog about the storage work they're doing. Just because it's quiet doesn't mean they're not beavering away.
At the last storage meeting we had a look at the coming storage meetings - not our own but the ones outside GridPP. There were storage talks at ISGC and CHEP, we looked at some of those. The next pre-GDB or GDB is supposed to be about storage although the agenda was a bit bare last I looked. There will be a workshop at DESY focusing on WLCG's usage of SRM, with the developers from both sides, so to speak. Preparations are ongoing for the next OGF - mainly documents that need writing, we still need an "experiences" document describing interoperation issues at the API level. There's a hepix coming up (agenda), in Sweden - usually we have an interest in the filesystem part as well as the site management. Then there is a storage meeting 2-3 July at RAL, following hepsysman on 0-1 July.
27 April 2009
26 March 2009
More on CHEP
Right I meant to write more about stuff that's going on here but the network is somewhat unreliable (authentication times out and reauthentication is not always possible). Anyway, I am making copious notes and will be making a full report at the next storage meeting - Wednesday 8 April.
If I shall summarise the workshop, from a high level data storage/mgmt perspective, I'd say it's about stability, scaling/performance, data access (specifically xrootd and http), long term support, catalogue synchronisation, interoperation, information systems, authorisation and ACLs, testing, configuration, complexity vs capabilities.
More details in the next meeting(s).
If I shall summarise the workshop, from a high level data storage/mgmt perspective, I'd say it's about stability, scaling/performance, data access (specifically xrootd and http), long term support, catalogue synchronisation, interoperation, information systems, authorisation and ACLs, testing, configuration, complexity vs capabilities.
More details in the next meeting(s).
22 March 2009
WLCG workshop part I
Lots of presentations and talks at the WLCG workshop. As usual much of the work is done in the coffee breaks.
From the storage perspective, there was talk about "SRM changes" which was news to me (experiments require (a) stability, and (b) change, you see). Upon closer investigation, it turns out to be about implementing the rest of the SRM MoU. One outstanding question is how these changes are implemented without impacting users (in a bad way).
Fair bit of talk about xrootd support. xrootd is considered a Good Thing(tm), but the DPM implementation is rather old (2 years). It is possible it can benefit from the new CASTOR implementation for 2.1.8.
Some talk about SRM performance. The dCache folks as usual have good suggestions, Gerd from NDGF suggests using SSL instead of GSI. I believe srmPrepareToGet should be synchronous when files are on disk, this should lead to a large performance increase. Talking to other data management people, we believe the clients should do the Right Thing(tm), so no changes required. Of course the server should be free to treat any request asynchronously if it feels it needs to do this, eg to manage load.
Talked to Brian Bockelman from U Nebraska; they have good experiences with (recent versions of) Hadoop, using BeStMan as the SRM interface.
More later...
From the storage perspective, there was talk about "SRM changes" which was news to me (experiments require (a) stability, and (b) change, you see). Upon closer investigation, it turns out to be about implementing the rest of the SRM MoU. One outstanding question is how these changes are implemented without impacting users (in a bad way).
Fair bit of talk about xrootd support. xrootd is considered a Good Thing(tm), but the DPM implementation is rather old (2 years). It is possible it can benefit from the new CASTOR implementation for 2.1.8.
Some talk about SRM performance. The dCache folks as usual have good suggestions, Gerd from NDGF suggests using SSL instead of GSI. I believe srmPrepareToGet should be synchronous when files are on disk, this should lead to a large performance increase. Talking to other data management people, we believe the clients should do the Right Thing(tm), so no changes required. Of course the server should be free to treat any request asynchronously if it feels it needs to do this, eg to manage load.
Talked to Brian Bockelman from U Nebraska; they have good experiences with (recent versions of) Hadoop, using BeStMan as the SRM interface.
More later...
08 March 2009
GridPP DPM toolkit v2.3.0 released
I've added a new command line tool to the DPM toolkit: dpm-delreplica. This just just a wrapper round the dpm_delreplica call in the python API and does exactly what it says on the tin. It arose after the guys at Oxford noted that there wasn't an easy way using existing tools to delete a replica of a file - it was either all or nothing.
One thing to note is that the tool will let you delete the last replica of a file, which then leaves a dangling entry in the DPM namespace that you can successfully do e.g. dpns-ls on, but cannot actually retrieve. As with all of these tools, I try to make each one as simple and self contained as possible (the Unix way) so I've not added any special checking to make sure that a replica isn't the last one. You have been warned.
The tool has been tested in a couple of places and seems to work fine. As always, feedback is welcome.
Cheers,
Greig
One thing to note is that the tool will let you delete the last replica of a file, which then leaves a dangling entry in the DPM namespace that you can successfully do e.g. dpns-ls on, but cannot actually retrieve. As with all of these tools, I try to make each one as simple and self contained as possible (the Unix way) so I've not added any special checking to make sure that a replica isn't the last one. You have been warned.
The tool has been tested in a couple of places and seems to work fine. As always, feedback is welcome.
Cheers,
Greig
13 February 2009
Gie's a job!
[Or for those who aren't Scottish: "Give me a job!" ;) ]
I know a few people read this blog so it seems like a good place for some advertising...
A new post-doctoral research associate position has opened up within the particle physics group at Edinburgh University to work on distributed storage management for the GridPP project. This has come about as I am leaving GridPP to move onto other things (physics analysis for LHCb, if you must know) so the project needs a replacement. It will be an exciting time for whomever gets the job since this year we will actually start to see data from the LHC experiments (fingers crossed)! Plus, Edinburgh is a great place to live and work.
All of the details about the position and the online application form can be found here. If you would like any more details please do get in touch.
In addition, the particle physics group in Edinburgh is advertising another job titled "Scientific Programmer". This system administrator position had two main responsibilities. First is the organisation and support of the groups computing needs and secondly to assist in the day-to-day operations of the Edinburgh Tier-2 grid services. All details can be found here. Again, get in touch if you have questions.
Cheers,
Greig
Update: You can get a full listing of the jobs available within the particle physics group at Edinburgh here:
http://www.ph.ed.ac.uk/particle-physics-experiment/positions.html
There's even an advanced fellowship position available if anyone is interested in doing some physics!
I know a few people read this blog so it seems like a good place for some advertising...
A new post-doctoral research associate position has opened up within the particle physics group at Edinburgh University to work on distributed storage management for the GridPP project. This has come about as I am leaving GridPP to move onto other things (physics analysis for LHCb, if you must know) so the project needs a replacement. It will be an exciting time for whomever gets the job since this year we will actually start to see data from the LHC experiments (fingers crossed)! Plus, Edinburgh is a great place to live and work.
All of the details about the position and the online application form can be found here. If you would like any more details please do get in touch.
In addition, the particle physics group in Edinburgh is advertising another job titled "Scientific Programmer". This system administrator position had two main responsibilities. First is the organisation and support of the groups computing needs and secondly to assist in the day-to-day operations of the Edinburgh Tier-2 grid services. All details can be found here. Again, get in touch if you have questions.
Cheers,
Greig
Update: You can get a full listing of the jobs available within the particle physics group at Edinburgh here:
http://www.ph.ed.ac.uk/particle-physics-experiment/positions.html
There's even an advanced fellowship position available if anyone is interested in doing some physics!
29 January 2009
GridPP DPM toolkit v2.2.0 released
Hot on the heels of v2.1.0 comes v2.2.0. This one contains a couple of new tools that have been created to allow sites to have a greater understanding of what is happening with their space tokens. These are:
* dpm-sql-spacetoken-usage
This displays information like:

* dpm-sql-spacetoken-list-files

Unfortunately, I have had to use some SQL to directly query the DB as the API doesn't support this functionality. I'm hoping that the small DB schema change in v1.7.0 of DPM doesn't break these tools too much... These tools were born out of some discussion which has taken place over the past couple of days on our gridpp-storage mailing list (anyone can join!). Thanks to those who tested out the initial releases of the tools.
I have also made another change to dpns-su. I have added another new switch (-s, --summary) for dpns-du which will present a summary of the total size under a target directory rather than the default behaviour which displays the summary for every sub-dir under the target.
You can get it from the usual place (although it will take a day for te yum repodata to update). Again, the release notes on the wiki will be updated at some stage...
* dpm-sql-spacetoken-usage
This displays information like:

* dpm-sql-spacetoken-list-files

Unfortunately, I have had to use some SQL to directly query the DB as the API doesn't support this functionality. I'm hoping that the small DB schema change in v1.7.0 of DPM doesn't break these tools too much... These tools were born out of some discussion which has taken place over the past couple of days on our gridpp-storage mailing list (anyone can join!). Thanks to those who tested out the initial releases of the tools.
I have also made another change to dpns-su. I have added another new switch (-s, --summary) for dpns-du which will present a summary of the total size under a target directory rather than the default behaviour which displays the summary for every sub-dir under the target.
You can get it from the usual place (although it will take a day for te yum repodata to update). Again, the release notes on the wiki will be updated at some stage...
23 January 2009
GridPP DPM toolkit v2.1.0 released
I've built a new release of the DPM admin toolkit. This one contains a couple of new tools that have been created by Sam Skipsey. They both present the user with a breakdown of the storage used in the DPM per user/group. One tool uses the DPM python API to do this (and is correspondingly slow) while the other directly talks to the DPM database using the python SQL module. Fingers crossed that this should present the same numbers as are calculated by the GridppDpmMonitor.
There is also a new switch for dpns-du which stops directories of zero size being printed to stdout. Yes Winnie, this one's for you.
You can get it from the usual place. Some of the release notes have to be updated for the new tools as I haven't got round to that yet...
There is also a new switch for dpns-du which stops directories of zero size being printed to stdout. Yes Winnie, this one's for you.
You can get it from the usual place. Some of the release notes have to be updated for the new tools as I haven't got round to that yet...
05 January 2009
The evolution of storage in 2008

I've been running my WLCG storage version monitoring system for 1 year so I thought now would be a prudent time to have a quick review of the changes in the storage infrastructure over the past year. The above image shows the count of each different version of the SRM2.2 storage middleware that is deployed on the Grid each day. Over the course of the year the number of deployed SRM2.2 endpoints increased steadily from ~100 to >250.
The pie charts below show the breakdown (as of today) for the different versions of DPM, dCache and CASTOR that are running on the Grid. There are also 20 instances of StoRM out there, but StoRM does not appear to return versioning information from an srmPing operation so it's not possible to tell what version is deployed.



DPM clearly dominates in terms of number of running instances. Hopefully CERN doesn't do something crazy like drop support for it! It's interesting to see that there are still many old versions of the software running at sites. Perhaps this is an indication of the success of SRM in that all of these different implementations are still talking to each other.
01 December 2008
RFIO testing at Liverpool
The guys at Liverpool have been doing some very interesting performance testing of different RFIO READAHEAD buffer settings for the RFIO clients on their worker nodes. Using real ATLAS analysis jobs they have seen significant performance improvements when using large (i.e. 128MB) buffer sizes, both in terms of the total amount of data transferred during any job and the CPU efficiency.
http://northgrid-tech.blogspot.com/2008/12/rfio-tuning-for-atlas-analysis-jobs.html
http://northgrid-tech.blogspot.com/2008/12/rfio-tuning-for-atlas-analysis-jobs.html
17 November 2008
What I did in my CERN vacation
"On the first day of my CERN vacation, I arrived." ...Er.
In approximate order of usefulness, this is what I managed to get done at the 2.5 day workshop last week (I'll insert more stuff as I remember...) Other people should report on the non-storage.
That's from a first pass through my notes. Hey ho.
In approximate order of usefulness, this is what I managed to get done at the 2.5 day workshop last week (I'll insert more stuff as I remember...) Other people should report on the non-storage.
- Thanks to the ever-helpful EGEE project office, got my paperwork renewed. Hooray!
- Working with Jan to deploy the CIP (CASTOR Information Provider) at CERN. Hooray!
- Catching up with the rest of the CASTOR team and getting lots of CASTOR related notes. There's a lot of new stuff in 2.1.8 (which can be deployed without GSIRFIO), and some strategic planning. xrootd is considered important strategically. Lots of other proposed developments. There is even a suggestion to investigate using Lustre for CASTOR. And how to best provide POSIX access?
- Kickstarting some work with DPM and dCache people. Even interoperation work is not completed and there are lots of little things to follow up on. For example, many SEs support xrootd but not necessarily interoperatingly. SE support for checksumming has improved a lot recently so is becoming increasingly promising.
- General GridPP-storage related stuff: priorities, experiment planning, site recovery from downtime.
- Catching up with Steven Newhouse over dinner Friday, talking about among other things standardisation work in EGEE (SRM, GLUE, etc), and EGI.
- Learning about the experiments storage experiences at the workshop. I heard both "it is too complex" and "we should make use of richer functionality". Made notes we should discuss in the storage meetings. Middleware plans are particularly important when there is no rollback out of an upgrade.
- Installed Capacity discussions. This should have been higher up this list as it was my primary reason for being there(!) but we only covered about 5% of what we ought to have covered. Still, 5% is better than 0%, and it was enough to solve 1 of my 7-8 remaining open use cases because dCache does something similar but complicatedlier. More on this later.
- FTS monitoring. Talked to Ricardo da Rocha who wants to do visualisation of FTS transfers. Well, whaddayaknow, we (GridPP) have already done this: Gidon built a version for me for the EGEE user forum in 2007 in Manchester, based on his work with the RTM. It uses RGMA monitored transfers, sped up x100 to make it look more interesting. Gidon gave me the source before he left. Unless someone from GridPP wishes to volunteer, I'll hand it over to Ricardo along with a suggestion to keep the "GridPP" sticker and give credit to Gidon.
- I am coordinating some additional work on SRM and SRB interoperation (beyond what we've achieved previously, I hope). I discussed my requirements for FTS with Paolo, Àkos, Gavin, et al. Simon Lin was there from ASGC so I got an update on Fu-Min's SRM-to-SRB layer.
- I've started using ROOT for some of the testing at RAL (obviously for rootd testing for LHCb) - some new features in PROOF may come in handy if we're to extend this.
That's from a first pass through my notes. Hey ho.
10 November 2008
Edinburgh dCache is dead. Long live DPM!
Today is a sad day in the world of Edinburgh storage. The long serving and (semi-)reliable dCache storage element has now been retired. It's had a hard life, with many ups and downs, particularly in it's youth. However, as it matured it grew into a dependable work horse for our local physics analyses. Unfortunately, the hardware is now old and creaking and the effects of the credit crunch have even managed to propagate all the way to the top of our ivory tower (i.e., electricity has gone up). These effects combined to force us to put dCache to sleep in a peaceful and humane manner at the end of last week.
However, never fear, all is not lost. We have been successfully using DPM for data access for many months now. We still have the occassional Griddy problem with it, but it is growing up to fill the void left behind by it's half brother. Long live DPM!
However, never fear, all is not lost. We have been successfully using DPM for data access for many months now. We still have the occassional Griddy problem with it, but it is growing up to fill the void left behind by it's half brother. Long live DPM!
24 October 2008
Monitoring space token ACLs

I have extended my space token monitoring to pick up the ACLs (technically the GlueVOInfoAccessControlBaseRule) about each space token that is published in the information system fro each site, SE and VO. This is updated each day and you can see the table of results here. The point of this is to make it easier (i.e. no horrible ldapsearch'ing) to check the deployment status of the tokens and the ability of certain VOMs roles to write files into them. Of course, this assumes that the advertised permissions do in fact match those on the SE, which in turn relies on the GIPs being correct. YMMV.
23 October 2008
NGS and GridPP - storage future?
The GridPP/NGS pow-wow yesterday was very useful. For storage, what can we do given that GridPP runs SRM, and the NGS uses SRB, distributed filesystems, Oracle, and OGSA-DAI?
We could of course look at interoperability: previously we achieved interoperation between SRM and SRB using gLite. (In GIN-ese, "interoperation" loosely speaking applies more than a works-for-now hack than "interoperability" which is meant to be a long-term solution.)
However, not many people really need interopera* between SRM and SRB at the moment, and when they do presumably the ASGC thingy will be ready. My observation would be that no one size fits all, different things do different things differently - we should not persuade NGS to run SRM any more than they should persuade us to store our data in SRB.
What I suggest we could more usefully do is to look at the fabric: we all (i.e. sites) buy disks and have filesystems and operating systems that need patching and tuning.
We could of course look at interoperability: previously we achieved interoperation between SRM and SRB using gLite. (In GIN-ese, "interoperation" loosely speaking applies more than a works-for-now hack than "interoperability" which is meant to be a long-term solution.)
However, not many people really need interopera* between SRM and SRB at the moment, and when they do presumably the ASGC thingy will be ready. My observation would be that no one size fits all, different things do different things differently - we should not persuade NGS to run SRM any more than they should persuade us to store our data in SRB.
What I suggest we could more usefully do is to look at the fabric: we all (i.e. sites) buy disks and have filesystems and operating systems that need patching and tuning.
- Procurement: sharing experiences, maybe even common tender at sites;
- Infrastructure: how to structure storage systems (topology, networks etc);
- Distributed filesystems?
- Optimisation and tuning: OS, networks, filesystems, drivers, kernels, etc;
- Technology watch: sharing experiences with existing technology (hardware) and tracking and testing new technology (e.g. SSD)
21 October 2008
GridPP DPM toolkit v2 released
I've just packaged up and released v2 of the GridPP DPM toolkit. You can find the latest information and installation instructions on the wiki. There have been a few significant changes with this release, hence the change in the major version number. In summary, the changes are as follows:
* A new naming convention. All tools have been renamed from gridpp_* to dpm-* or dpns-* to bring them into line with the existing DPM client tools (Graeme will be happy...).
* All tools are now installed in /opt/lcg/bin rather than /usr/bin (again to bring them into line with the existing client tools).
* A new tool called dpns-find. This allows a user to specify a path and a FILENAME. The tool will then recursively search the directory tree for all files that match FILENAME and print out the full path to that file to stdout. This tool doesn't attempt to reproduce the functionality of the UNIX find command; I'll see if I can extend the functionality in a future release.
* Michel Jouvin's dpm-listspaces has been updated to the latest release (which will work with the 1.6.-11 branch of DPM).
The yum repository repodata should be updated tonight. As always, let me know if there are problems with the tools or if you want to add one of your own.
* A new naming convention. All tools have been renamed from gridpp_* to dpm-* or dpns-* to bring them into line with the existing DPM client tools (Graeme will be happy...).
* All tools are now installed in /opt/lcg/bin rather than /usr/bin (again to bring them into line with the existing client tools).
* A new tool called dpns-find. This allows a user to specify a path and a FILENAME. The tool will then recursively search the directory tree for all files that match FILENAME and print out the full path to that file to stdout. This tool doesn't attempt to reproduce the functionality of the UNIX find command; I'll see if I can extend the functionality in a future release.
* Michel Jouvin's dpm-listspaces has been updated to the latest release (which will work with the 1.6.-11 branch of DPM).
The yum repository repodata should be updated tonight. As always, let me know if there are problems with the tools or if you want to add one of your own.
16 October 2008
GridppDpmMonitor v0.0.4 released


I've made another release of GridppDpmMonitor. This adds support for viewing the space used per user (i.e. DPM virtual uid) and per group (DPM virtual gid). I've removed most of the DN information so that user privacy is retained.
You'll have to wait until tomorrow for the yum repository to be rebuilt. See previous postings on this subject to get the location of the wiki and repo.
The monitoring will be useful to see which users are exceeding their "quota", but it does not enforce a quota on the users. At the moment, there is no quotaing in the Grid SEs. However, this tool does give site admins is the ability to go and beat local users round the head with a big stick if they go over their allocation. CMS want 1TB for local users; I don't think there is a similar requirement from ATLAS, yet.
09 October 2008
New release of GridppDpmMonitor

I've made a new release of the GridppDpmMonitor. This adds a new plot which shows you the breakdown of failures according to the error message that is stored by DPM (annoyingly, this is often blank). I have also modified the existing graphs such that the client DN's are not shown (I got into trouble for this). Instead, I just show the common name (CN) of the DN, which is much more acceptable.
You can go to the usual place for instructions.
06 October 2008
Tier-2 storage at the GDB
I've been asked to talk about how we organise Tier-2 storage within the UK at this week's Grid Deployment Board. I'll also mention a couple of things where we think the middleware is lacking, i.e.,
* user quotas
* access control on SRM spaces
* administration tools for performing common tasks
* monitoring and alarms
If there is anything that comes to mind, then drop me a comment before Wednesday.
* user quotas
* access control on SRM spaces
* administration tools for performing common tasks
* monitoring and alarms
If there is anything that comes to mind, then drop me a comment before Wednesday.
15 September 2008
Update on CASTOR infoprovider deployment
It should have been done quite a few weeks ago, when we discussed it in a CASTOR experiments meeting, but deployment was postponed first when the 6.022*(10**23) bug hit (without stagers, the dynamic information provider is not terribly useful), and then I was away for some weeks for GridPP and AHM and suchlike.
So the new infoprovider is now rescheduled for deployment at 23.09.08 at 09:00 BST. Dutyadmin will schedule a short at-risk period for CASTOR.
The new provider will publish also "unreachable" storage spaces, e.g. disk pools with no space token descriptions, according to WLCG GDB accountingforeverythingism. Moreover, it will
abu^W use the "reserved space" attribute to publish whether space has been "reserved" for a VO. Not to be confused with SRM reservedSpace.
Note that like the previous versions, this one publishes only online (disk) space. A version that publishes nearline (tape) is in the pipeline but not with a high priority.
Currently discussions are ongoing whether it is appropriate to publish space as "reserved" (in the sense above) if it has no space token descr. I publish it in the version which will go out next week, but there is a development version which doesn't.
This version of the information provider was given to CERN and (INFN or ASGC) back in August, but it is not known whether they have deployed it.
So the new infoprovider is now rescheduled for deployment at 23.09.08 at 09:00 BST. Dutyadmin will schedule a short at-risk period for CASTOR.
The new provider will publish also "unreachable" storage spaces, e.g. disk pools with no space token descriptions, according to WLCG GDB accountingforeverythingism. Moreover, it will
abu^W use the "reserved space" attribute to publish whether space has been "reserved" for a VO. Not to be confused with SRM reservedSpace.
Note that like the previous versions, this one publishes only online (disk) space. A version that publishes nearline (tape) is in the pipeline but not with a high priority.
Currently discussions are ongoing whether it is appropriate to publish space as "reserved" (in the sense above) if it has no space token descr. I publish it in the version which will go out next week, but there is a development version which doesn't.
This version of the information provider was given to CERN and (INFN or ASGC) back in August, but it is not known whether they have deployed it.
14 September 2008
Storage@GridKa school of computing
The GridKa school of computing was last week. There are a few storage related talks which you can find on the agenda.
* I gave an overview talk about storage on the Grid.
* There was a dCache tutorial session which gave a good summary of all things SRM2.2.
* Sun Microsystems had some stuff to say about Lustre and pNFS (not the dCache PNFS!).
There were also presentations about local user analysis and a session on ROOT/PROOF (which is closely related to local analysis work, although not in the Grid-storage sense). For some reason the material for those talks is not available yet. You can see the full agenda here.
* I gave an overview talk about storage on the Grid.
* There was a dCache tutorial session which gave a good summary of all things SRM2.2.
* Sun Microsystems had some stuff to say about Lustre and pNFS (not the dCache PNFS!).
There were also presentations about local user analysis and a session on ROOT/PROOF (which is closely related to local analysis work, although not in the Grid-storage sense). For some reason the material for those talks is not available yet. You can see the full agenda here.
21 August 2008
RAL Castor issues also affecting LHCb
The Oracle problems that heve been an issue with the CASTOR ATLAS system at RAL also appear to be affecting LHCb according to an email from Bonny this morning. Problems started at 2008-08-20 10:56.
18 August 2008
dpm-drain
Just a heads up for any DPM users - We might have discovered an issue with the draining files from a pool. If for any reason dpm thinks there's no allocatable space (not the same thing as Free space - its assuming space reservations are going to be filled) then it may move the data out of that pool and into another (such as generalPool).
Even worse it may remove those files out of a spacetoken.
I shall update when I have more information. (needless to say we stopped draining uki-scotgrid-glasgow pools this morning)
See Bug #40273
Even worse it may remove those files out of a spacetoken.
I believe the problem you've run into is that dpm-drain is moving the files out of their space and putting the new copy in no particular space. The ATLAS pool would be preferentially chosen for ATLAS files but the free (non space reservation) portion has been exhausted, so it falls backs to the general pool.
I shall update when I have more information. (needless to say we stopped draining uki-scotgrid-glasgow pools this morning)
See Bug #40273
GridKa school of computing 2008
I have been asked to present a talk titles "The Importance of Data Storage" at this years GridKa school of computing. In particular, I have been asked to discuss issues like:
* computing and data storage: differences in the challenges.
* several examples of communities needing large amounts of data on the grid (if possible, communities having different access models).
* usage of different storage technologies (disk, tape, solid state,...).
* different tools for storing huge amounts of data.
If anyone has any pertinent ideas then I'd like to know about them, particularly when it comes to non-HEP users of Grid storage.
Cheers,
Greig
* computing and data storage: differences in the challenges.
* several examples of communities needing large amounts of data on the grid (if possible, communities having different access models).
* usage of different storage technologies (disk, tape, solid state,...).
* different tools for storing huge amounts of data.
If anyone has any pertinent ideas then I'd like to know about them, particularly when it comes to non-HEP users of Grid storage.
Cheers,
Greig
GridPP DPM toolkit 1.3.0 released
I meant to post about this last week, as I have released a new version of my DPM admin toolkit. This release includes a new tool called gridpp_dpm_dpns_du. This reports on the usage of directories in the DPNS namespace. This tool is something that CMS people at Bristol were asking for such that users could manage their own space.
$ gridpp_dpm_dpns_du -h
usage: gridpp_dpm_dpns_du /dpm/path/to/directory
options:
-h, --help show this help message and exit
-s, --si Use powers of 1000, not 1024.
-xEXCLUDE, --exclude=EXCLUDE
Directory to ignore.
One thing that I have noticed is that the tool sometimes claims that a directory contains (say) 914354654K. However, when you dpns-ls -l the directory it does not contain any files or sub-dirs. Deeper investigation using dpns-ls --delete shows that DPM still has some remnant of an old file replica which was previously in that directory, but has now been marked as "D" for deleted. If there are no problems, these files can be removed with rfrm. Let me know if you find any other bugs.
Note that the rpm depends on DPM-interfaces > 1.6.11-4 due to the inclusion of the dpm-listspaces tool (which needs the latest API). You can find the latest rpm here.
$ gridpp_dpm_dpns_du -h
usage: gridpp_dpm_dpns_du /dpm/path/to/directory
options:
-h, --help show this help message and exit
-s, --si Use powers of 1000, not 1024.
-xEXCLUDE, --exclude=EXCLUDE
Directory to ignore.
One thing that I have noticed is that the tool sometimes claims that a directory contains (say) 914354654K. However, when you dpns-ls -l the directory it does not contain any files or sub-dirs. Deeper investigation using dpns-ls --delete shows that DPM still has some remnant of an old file replica which was previously in that directory, but has now been marked as "D" for deleted. If there are no problems, these files can be removed with rfrm. Let me know if you find any other bugs.
Note that the rpm depends on DPM-interfaces > 1.6.11-4 due to the inclusion of the dpm-listspaces tool (which needs the latest API). You can find the latest rpm here.
20 July 2008
GridPP DPM toolkit v1.2.0-1 released
I have made a new release (v1.2.0-1) of the GridPP DPM admin toolkit. This adds in a new tool written by Michel Jouvin (GRIF, France) called "dpm-listspaces". Michel's aim with this new tool is that it can be used as a replacement for both dpm-qryconf and dpm-getspacemd. It is Michel's intention to get this into the main release of DPM, but as an interim solution I have included it in the toolkit. You can find installation instructions at the above link.
It should be noted that this release has a dependency on DPM-interfaces >= 1.6.11-4 which hasn't been released yet. The reason for this is that the very latest version of the DPM python API is required for dpm-listspaces to work. If you want to have a look, DPM-interfaces v1.6.11-4 can be found in the ETICS repo here. This is compatible with v1.6.10 of DPM (I've installed it at Edinburgh).
Finally, dpm-listspaces doubles up as the new GIP for DPM. It has a --gip option which prints out the appropriate bit of LDIF conforming to GLUE 1.3. You don't have to worry about this just now, I'll talk more about it at a later date.
It should be noted that this release has a dependency on DPM-interfaces >= 1.6.11-4 which hasn't been released yet. The reason for this is that the very latest version of the DPM python API is required for dpm-listspaces to work. If you want to have a look, DPM-interfaces v1.6.11-4 can be found in the ETICS repo here. This is compatible with v1.6.10 of DPM (I've installed it at Edinburgh).
Finally, dpm-listspaces doubles up as the new GIP for DPM. It has a --gip option which prints out the appropriate bit of LDIF conforming to GLUE 1.3. You don't have to worry about this just now, I'll talk more about it at a later date.
02 June 2008
GridppDpmMonitor

People often state that DPM is a bit of a black box. That it, they know it's working, but aren't really sure what it is doing or who is using it. To help address this problem, over the past week or so I've put together some some DPM monitoring to help visualise all of the information which is usually locked in the MySQL database. Hopefully, this will give sites an idea of what DPM is doing and make it easier to debug problems with data access.
The system works using GraphTool (I've mentioned this numerous times before) and is heavily influenced by Brian Bockleman's dCache monitoring tool. I have constructed a variety of queries which pull information directly from the DPM MySQL database about transfer requests. The monitoring is basically a set of python scripts and xml files. To ease installation and help resolve the dependencies, I've packaged (again, thanks Brian) the monitoring up into an rpm called GridppDpmMonitor and hosted it in the HEPiX sys-man yum repository. Instructions for configuration are here, along with some example plots.
I'm still working out exactly what plots we want to see and constructing the appropriate SQL queries. It's a beta (i.e. not perfect) release but I would appreciate any comments you have. The system is already running at Edinburgh, Durham and Cambridge (thanks Phil and Santanu!).
You should note that getting a transfer rate plot doesn't actually appear to be possible. If anyone can work out a way of doing it from the dpm_db tables then let me know. Also, having this monitoring linked into Nagios would be great, but that is something for the future.
As always, contributions are welcome!
29 May 2008
Monitoring grid data transfers
It has become increasingly clear during the CCRC exercises that GridView is not a good place to go if you want to get a good overview of current Grid data transfer. Simply put, it does not have all of the information required to build such a global view. It is fine if you just want to see how much data is pumping out of CERN, but beyond that I'm really not sure what it is showing me. For a start, no dCache publishes its gridftp records into GridView. Since there are ~70 dCache sites out there (5 of which are T1s!), there is a lot of data missing. There also seems to be data to/from T2s that is missing since the GridView plots I posted a few days ago show a tiny T2 contribution which just doesn't match up with what we are seeing in the UK at the moment.
To get a better idea of what is going on, you've really got to head to the experiment portals and dashboards. Phedex for CMS, DIRAC monitoring for LHCb and the ATLAS dashboard (sorry, not sure about ALICE...) all give really good information (rates, successes, failures) about all of the transfers taking place.
(This being said, I do find the ATLAS dashboard a little confusing - it's never entirely clear where I should be clicking to pull up the information I want.)
You can also go to the FTS servers and get information from their logs. In the UK we have a good set of ganglia-style monitoring plots. This provides an alternative view of the information from the experiment dashboards since it shows transfers from all VOs managed by that FTS instance. Of course, this doesn't give you any information about transfers not managed by that server, or transfers not managed by any FTS anywhere. As I've mentioned before, I put together some basic visualisation of FTS transfers which I find good to get a quick overview of the activity in the UK.
Summary: I won't be going back to GridView to find out the state of current data transfers on the Grid.
To get a better idea of what is going on, you've really got to head to the experiment portals and dashboards. Phedex for CMS, DIRAC monitoring for LHCb and the ATLAS dashboard (sorry, not sure about ALICE...) all give really good information (rates, successes, failures) about all of the transfers taking place.
(This being said, I do find the ATLAS dashboard a little confusing - it's never entirely clear where I should be clicking to pull up the information I want.)
You can also go to the FTS servers and get information from their logs. In the UK we have a good set of ganglia-style monitoring plots. This provides an alternative view of the information from the experiment dashboards since it shows transfers from all VOs managed by that FTS instance. Of course, this doesn't give you any information about transfers not managed by that server, or transfers not managed by any FTS anywhere. As I've mentioned before, I put together some basic visualisation of FTS transfers which I find good to get a quick overview of the activity in the UK.
Summary: I won't be going back to GridView to find out the state of current data transfers on the Grid.
27 May 2008
CCRC'08 data transfers (part 2)


Just thought I would post a couple of plots to show the data transfers over the past couple of weeks. Things seem to have reached their peak of ~2GB/s last week and have now reached a steady state of ~1.2GB/s. These plots show transfers from all sites to all sites and it looks like the vast majority of the data appears to be going to the T1s.
I think during the ATLAS FDR exercises there will be much more data coming to the T2s from their associated T1. This should be good to help test out all that new storage that has been deployed.
DPM admin toolkit now available
I have created a small set of DPM administration tools which use the DPM python API. They have already proved useful to some sites in GridPP, so I hope they can help others as well. The tools are packaged up in an rpm (thanks to Ewan MacMahon for writing the .spec) and hosted in a yum repo to ease the installation and upgrade procedure. Information about current list of available tools, installation instructions and the bug reporting mechanism can be found here.
I'm sure there will be bugs that I have missed, so please report them to me (or via the savannah page). I would encourage people to contribute patches and their own tools if they find something missing from the current toolkit.
I'm sure there will be bugs that I have missed, so please report them to me (or via the savannah page). I would encourage people to contribute patches and their own tools if they find something missing from the current toolkit.
12 May 2008
DPM admin tools
I have started to put together a set of scripts for performing common (and possibly not-so-common) administration tasks with DPM. This uses the python interface provided by the DPM-interfaces package. It's definitely a work in progress, but you can you can checkout the latest set of scripts from here (assuming you have a CERN account):
isscvs.cern.ch:/local/reps/lhcbedinburgh/User/gcowan/storage/dpm/admin-tools
If not, then I have put them in a tarball here.
They are very much a work in progress, so things will be changing over the next few weeks (i.e., keep a lookout for changes). As always, contributions are welcome. I should probably package this stuff up as an rpm, but haven't got round to that yet. I should also put them into the sys-admin repository and write some documentation (other than the -h option). Like I say, contributions are always welcome...
isscvs.cern.ch:/local/reps/lhcbedinburgh/User/gcowan/storage/dpm/admin-tools
If not, then I have put them in a tarball here.
They are very much a work in progress, so things will be changing over the next few weeks (i.e., keep a lookout for changes). As always, contributions are welcome. I should probably package this stuff up as an rpm, but haven't got round to that yet. I should also put them into the sys-admin repository and write some documentation (other than the -h option). Like I say, contributions are always welcome...
CCRC May'08 data transfers
The plots above shows the slow ramp up in data transfers being run by the experiments during the May phase of CCRC. Clearly CMS are dominating proceedings at the moment. It's not clear what has happened to ATLAS after an initial spurt of activity. Hopefully they get things going soon, otherwise the Common elememt of CCRC might not be achieved. What is good is that a wide variety of sites are involved. You can even see the new Edinburgh site in there (although it is coming up as unregistered in GridView).
I'll take this opportunity to remind everyone of the base version of the gLite middleware that sites participating in the CCRC exercise are expected to be running. Have a look at the list here.
24 March 2008
Grid storage not working?
Well, going by what I heard last week at LHCb software week, I think the answer to this question is "No". The majority of the week focussed on all the cool new changes to the core LHCb software and improvements to the HLT, but there was an interesting session on Wednesday afternoon covering CCRC and more general LHCb computing operations. The point was made in 3 (yes, 3!) separate talks that LHCb continue to be plagued with storage problems which prevent their production and reconstruction jobs from successfully completing. The main issue is the instability of using local POSIX-like protocols to remotely open files on the grid SE from jobs running on the site WNs. From my understanding, this issue could broadly be separated into two categories:
1. Many of the servers being used have been configured in such a way that if a job held a file in an open state for longer than (say) 1 day, the connection was being dropped, causing the entire job to fail.
2. Sites have been running POSIX-like access serices on the same hosts that are providing the SRM. This isn't wrong, but is definitely not recommended due to the load on the system. Anyway, the real problem comes when the SRM has to be restarted for some reason (most likely an upgrade) and the site(s) appear to have just been restarting all services on the node which again resulted in any open file connections being dropped and jobs subsequently failing. I thought it was basic knowledge that everyone knew about, but apparently I was wrong.
LHCb seem to be particularly vulnerable as they have long running reconstruction jobs (>33 hours),resulting in low job efficiency when the above problems rear their ugly heads. I would be interested in comments from other experiments on these observations. Anyway, the upshot of this is that LHCb are now considering on copying data files locally prior to starting their reconstruction jobs. This won't be possible for user analysis jobs, which will be accessing events from a large number of files. Copying all of these locally isn't all that efficient, nor do you know a priori how much local space the WN has available.
xrootd was also proposed as an alternative solution. Certainly dCache, CASTOR and DPM all now provide an implementation of the xrootd protocol in addition to native dcap/rfio, so getting it deployed at sites would be relatively trivial (some places already have it available for ALICE). I don't know enough about xrootd to comment, but I'm sure if properly configured it would be able to deal with case 1 above. Case 2 is a different matter entirely... It should be noted (perhaps celebrated?) that none of the above problems have to do with SRM2.2.
Of course, LHCb only require disk at Tier-1s, so none of this applies to Tier-2 sites. Also, they reported that they saw no problems at RAL: well done guys!
In addition, the computing team have completed a large part of the stripping that the physics planning group have asked for (but this isn't really storage related).
1. Many of the servers being used have been configured in such a way that if a job held a file in an open state for longer than (say) 1 day, the connection was being dropped, causing the entire job to fail.
2. Sites have been running POSIX-like access serices on the same hosts that are providing the SRM. This isn't wrong, but is definitely not recommended due to the load on the system. Anyway, the real problem comes when the SRM has to be restarted for some reason (most likely an upgrade) and the site(s) appear to have just been restarting all services on the node which again resulted in any open file connections being dropped and jobs subsequently failing. I thought it was basic knowledge that everyone knew about, but apparently I was wrong.
LHCb seem to be particularly vulnerable as they have long running reconstruction jobs (>33 hours),resulting in low job efficiency when the above problems rear their ugly heads. I would be interested in comments from other experiments on these observations. Anyway, the upshot of this is that LHCb are now considering on copying data files locally prior to starting their reconstruction jobs. This won't be possible for user analysis jobs, which will be accessing events from a large number of files. Copying all of these locally isn't all that efficient, nor do you know a priori how much local space the WN has available.
xrootd was also proposed as an alternative solution. Certainly dCache, CASTOR and DPM all now provide an implementation of the xrootd protocol in addition to native dcap/rfio, so getting it deployed at sites would be relatively trivial (some places already have it available for ALICE). I don't know enough about xrootd to comment, but I'm sure if properly configured it would be able to deal with case 1 above. Case 2 is a different matter entirely... It should be noted (perhaps celebrated?) that none of the above problems have to do with SRM2.2.
Of course, LHCb only require disk at Tier-1s, so none of this applies to Tier-2 sites. Also, they reported that they saw no problems at RAL: well done guys!
In addition, the computing team have completed a large part of the stripping that the physics planning group have asked for (but this isn't really storage related).
04 March 2008
Visualising FTS transfers

As always, monitoring is a hot topic. Sites, experiments and operations people all want to know what Grid services are doing and how this is impacting on their work. In particular, it is clear from todays GDB that monitoring of the FTS is important. The above graph shows the output of a script which I have put together over the past day which queries the RAL FTS service for information about its channels, their transfer rates and information about the number of jobs that are scheduled to be transferred. In fact, I don't query the FTS directly, but use some CGI that Matt Hodges at RAL set up (thanks Matt!). It's a prototype at the moment, but I think it could be one useful way of looking at the data and getting an overview of the state of transfers.
You can see the latest plots for the WLCG VOs here. They are updated hourly. I still need to play about with the colours to try and improve the visual effect. It would be great if the line thickness could be varied with transfer rate, but I don't think GraphViz/pydot can do that.
22 February 2008
dCache configuration, graphviz style

I don't know about anyone else, but I'm fed up having to try and debug different site's PoolManager.conf files, especially with all this LinkGroup stuff going on. I find it too too hard to manually parse a file when it stretches to 100's of lines, making it virtually impossible to know if there are any mistakes.
In an effort to try and improve the situation, I put together a little python script last night that converts a PoolManager.conf into a .dot file. This can then be processed by GraphViz to produce a structured graph of the dCache configuration. You can see some examples of currently active dCache configurations here. The above plot shows the config at Edinburgh.
I have been creating both directional (dot) and undirectional (neato) graphs. At the moment, the most useful one is the dot plot. I'm still exploring what neato can be used for.
I think the fact that we even have to consider looking at things this way tells you two things:
1. dCache is a complex beast, with a multitude of different ways of setting things up (which has both pros and cons).
2. The basic configuration really has to be improved to save multiple man-hours that are spent across the Grid trying to debug basic problems.
At the moment, this system is only a prototype. It is intended as an aide to understanding dCache configuration and looking for potential bugs. As always, comments are welcome.
PS Thanks to Steve T for inspiring me to work on this following his graphing glue project.
16 February 2008
The CASTOR beaver

It's not often in my work that I get to talk about beavers, but I figured this was appropriate for the storage blog. I discovered yesterday that Castor is the single remaining genus of the family Castoridae, of which the beaver is a member. I think this explains the logo (both new and old).
14 February 2008
Upcoming Software
Not strictly GridPP but storage related. Discovered in a recent LWN Article some info about Coherent Remote File System (CRFS) as yet another possible NFS replacement.
05 February 2008
CMS CCRC storage requirements
Since I've already talked about ATLAS tonight, I thought it might be useful to mention CMS. The official line from the CCRC meeting that I was at today is that Tier-2 sites supporting CMS should reserve space (probably wise to give them a couple of TBs). The space token should be assigned the CMS_DEFAULT space token *description*.
DPM sites should follow a similar procedure to that for ATLAS described below. dCache sites have a slightly tougher time of it. (Matt, Mona and Chris, don't worry, I hear your cries now...)
DPM sites should follow a similar procedure to that for ATLAS described below. dCache sites have a slightly tougher time of it. (Matt, Mona and Chris, don't worry, I hear your cries now...)
ATLAS CCRC storage requirements
For those of you reading the ScotGrid blog, you will have seen this already. Namely, that SRMv2 writing during CCRC (which started yesterday!) will happen using the atlas/Role=production VOMS role. Therefore sites should restrict access to the ATLASMCDISK and ATLASDATADISK space tokens to this role. To do this, release and then recreate the space reservation:
# dpm-releasespace --token_desc ATLASDATADISK
# dpm-reservespace --gspace 10T --lifetime Inf --group atlas/Role=production --token_desc ATLASDATADISK
Note that at Edinburgh I set up a separate DPM pool that was only writable by atlas, atlas/Role=production and atlas/Role=lcgadmin. When reserving the space, I then used the above command but also specified the option "--poolname EdAtlasPool" to restrict the space reservation to that pool (I also only gave them 2TB ;)
Also, for those interested, here's the python code (make sure you have DPM-interfaces installed and /opt/lcg/lib/python in yout PYTHONPATH).
# dpm-releasespace --token_desc ATLASDATADISK
# dpm-reservespace --gspace 10T --lifetime Inf --group atlas/Role=production --token_desc ATLASDATADISK
Note that at Edinburgh I set up a separate DPM pool that was only writable by atlas, atlas/Role=production and atlas/Role=lcgadmin. When reserving the space, I then used the above command but also specified the option "--poolname EdAtlasPool" to restrict the space reservation to that pool (I also only gave them 2TB ;)
Also, for those interested, here's the python code (make sure you have DPM-interfaces installed and /opt/lcg/lib/python in yout PYTHONPATH).
#! /usr/bin/env python
#
# Greig A Cowan, 2008
#
import dpm
def print_mdinfo( mds):
for md in mds:
print 's_type\t', md.s_type
print 's_token\t', md.s_token
print 's_uid\t', md.s_uid
print 's_gid\t', md.s_gid
print 'ret_pol\t', md.ret_policy
print 'ac_lat\t', md.ac_latency
print 'u_token\t', md.u_token
print 't_space\t', md.t_space
print 'g_space\t', md.g_space
print 'pool\t', md.poolname
print 'a_life\t', md.a_lifetime
print 'r_life\t', md.r_lifetime, '\n'
print '################'
print '# Space tokens #'
print '################'
tok_res, tokens = dpm.dpm_getspacetoken('')
if tok_res > -1:
md_res, metadata = dpm.dpm_getspacemd( list(tokens) )
if md_res > -1:
print_mdinfo( metadata)
01 February 2008
gLite 3.1 DPM logrotate bug
It's in savannah (#30874) but this one may catch out people who have installed the DPM-httpd. There's a missing brace that breaks logrotate on the machine.
29 January 2008
CASTOR dynamic information publishing
Folks, we now have dynamic data published for CASTOR. Yes, it's something we were supposed to do since the EGEE conference in Pisa(!), but only now has it percolated up through all the other tasks to become a high priority - otherwise the focus has been on CASTOR itself.
For details (and current limitations) of the implementation, please refer to: https://www.gridpp.ac.uk/wiki/RAL_Tier1_CASTOR_Accounting
For details (and current limitations) of the implementation, please refer to: https://www.gridpp.ac.uk/wiki/RAL_Tier1_CASTOR_Accounting
23 January 2008
CCRC confusion
So, which Tier-2s are involved in the February CCRC exercise? Does anyone know? What about the date that they will get involved? Do they need to have SRM2.2, or not? Some sources suggest they do, others suggest they don't. If anyone knows the answers to these questions, please email me. I think I'll start attending the daily meetings to find out what is going on.
Also, it turns out that although the 1.8.0-12 release of dCache was made sometime last week, it turns out that this is also the CCRC branch of dCache. Do you spot the difference? Good, then we can continue. This explains the weird naming convention that the dCache developers are using for all CCRC related releases, namely 1.8.0-12p1, 1.8.0-12p2 for patch versions 1 and 2 of the 1.8.0-12 branch. Hope that clears things up.
Also, it turns out that although the 1.8.0-12 release of dCache was made sometime last week, it turns out that this is also the CCRC branch of dCache. Do you spot the difference? Good, then we can continue. This explains the weird naming convention that the dCache developers are using for all CCRC related releases, namely 1.8.0-12p1, 1.8.0-12p2 for patch versions 1 and 2 of the 1.8.0-12 branch. Hope that clears things up.
Banned by SAM
Looks like the SAM people weren't very happy with the monitoring that I was running to summarise the status of storage resources on the Grid. In fact, they were so unhappy that they decided to block the IP address that I was using and switch off access to the /sqldb/ query path on their server! As such, the monitoring hasn't been working for the past few days.
I'll admit that I was putting a fair bit of load on their database since I was using a multithreaded application to request information about 6 different tests for ~200 SEs over the past 30 days, but I think this is a bit harsh. Another part of the problem is that the script seemed to trip up when processing information on a couple of sites (and it was always the same sites), leading to it continually requesting the same information. I'd love to debug why this was, but this is somewhat difficult when I can't access the DB.
I'm currently jumping through some hoops to try and get access to the new JSP endpoint. Hopefully this will be granted soon and I can update the application to deal with the new XML schema.
I'll admit that I was putting a fair bit of load on their database since I was using a multithreaded application to request information about 6 different tests for ~200 SEs over the past 30 days, but I think this is a bit harsh. Another part of the problem is that the script seemed to trip up when processing information on a couple of sites (and it was always the same sites), leading to it continually requesting the same information. I'd love to debug why this was, but this is somewhat difficult when I can't access the DB.
I'm currently jumping through some hoops to try and get access to the new JSP endpoint. Hopefully this will be granted soon and I can update the application to deal with the new XML schema.
16 January 2008
Monitoring SRM2.2 deployment
 Using a combination of the WLCG information system, srmPing from the StoRM SRM client, a multithreaded python script, GraphTool and Apache, I've set up some daily monitoring of all of the SRM v2.2 endpoints that are available on the Grid. This will help track deployment of the new software, allowing us to see which versions are running in production.
Using a combination of the WLCG information system, srmPing from the StoRM SRM client, a multithreaded python script, GraphTool and Apache, I've set up some daily monitoring of all of the SRM v2.2 endpoints that are available on the Grid. This will help track deployment of the new software, allowing us to see which versions are running in production.http://wn3.epcc.ed.ac.uk/srm/xml/
Using the cool GraphTool features, you can drill down into the data by typing dCache, CASTOR or DPM in the SRM_flavour box. You can also look at a particular countries endpoints by putting something like .uk in the endpoint box (for all UK sites). Hopefully poor old wn3.epcc can handle all this monitoring that it's doing!
One thing to note is that there is quite a variety of dCache 1.8.0-X out there. What are the developers playing at?
A slightly annoying feature is that srmPing requires a valid proxy, so I'll need to come up with a good way of creating a long-lived one.
Global dCache monitoring

It's been a while since my last post - been busy with some things that I will post about shortly. As you know, I've been running the GridPP SAM storage monitoring for the past few weeks. It looks like the dCache team got wind of this and have asked if I could set up something similar to summarise the SAM test results for all dCache sites in the WLCG information system. This is now done and the results can be seen above and at this new page in the dCache wiki:
http://trac.dcache.org/trac.cgi/wiki/MonitoringDcache
I don't seem to be able to get SAM results for the US Tier-2 sites, so I'll need to investigate this. The above link contains other useful information that I'll talk about shortly.
03 January 2008
dCache PostgreSQL monitoring


Happy New Year everyone!
Following a recommendation from the dCache developers, I set up some PostGreSQL monitoring using pgFouine. It is very simple to install and configure. The plots are generated automatically by the pgfouine tool in addition to giving a full breakdown of what queries took the longest time. This should be useful to let you understand what your database (and hence dCache) is doing. You can also use it to analyse the output of the VACUUM (FULL) ANALYSE command which should give you an idea as to how large the FSM should be set to (which is an important configuration parameter).
PS Fouine is French for stone marten, which is something like a weasel.
16 December 2007
Anyone for some dCache monitoring?

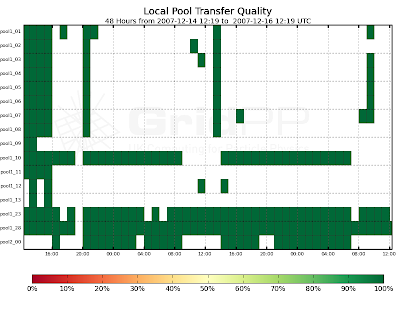
The above plots come from some new dCache monitoring that I have set up to study the behaviour of the Edinburgh production storage (srm.epcc.ed.ac.uk). This uses Brian Bockleman's GraphTool and some associated scripts to query the dCache billing database. You can find the full set of plots here (I know, it's a strange hostname for a monitoring, but it's all that was available):
http://wn3.epcc.ed.ac.uk/billing/xml/
GraphTool is written in python and uses matplotlib to generate the plots. Cherrypy is used for the web interface. The monitoring can't just be installed as an rpm: you need to have PostGreSQL 8.2 available; create a new view in the billing database; set up Apache mod_rewrite; ensure you have the correct compilers installed..., but these steps shouldn't be a problem for anyone.
I think you will agree that the monitoring presents some really useful views of what the dCache is actually doing. It's still a work in progress, but let me know when you want to set it up and I should be able to help.
It should be possible to do something similar for DPM in the coming weeks.
10 December 2007
DPM on SL4
Time to break out the champagne, it looks like DPM will be officially released in production on SL4 next Wednesday.
"Based on the feedback from PPS sites, we think that the following
patches can go to production next Wednesday:
# available on the linked GT-PPS ticket(s)
#1349 glite-LFC_mysql metapackage for SLC4 - 3.1.0 PPS Update 10
#1350 glite-SE_dpm_disk metapackage for SLC4 - 3.1.0 PPS Update 10
#1352 glite-SE_dpm_mysql metapackage for SLC4 - 3.1.0 PPS Update 10
#1541 glite-LFC_oracle metapackage for SLC4 - 3.1.0 PPS Update 10
#1370 R3.1/SLC4/i386 DPM/LFC 1.6.7-1 - 3.1.0 PPS Update 10"
Of course, some sites have been running SL3 DPM on SL4 for over a year and others have been running the development SL4 DPM in production for months. One warning I would give would be to make sure the information publishing is working, I've had a few problems with that in the past (in fact today I was battling with an incompatible version of perl-LDAP from the DAG repository).
"Based on the feedback from PPS sites, we think that the following
patches can go to production next Wednesday:
# available on the linked GT-PPS ticket(s)
#1349 glite-LFC_mysql metapackage for SLC4 - 3.1.0 PPS Update 10
#1350 glite-SE_dpm_disk metapackage for SLC4 - 3.1.0 PPS Update 10
#1352 glite-SE_dpm_mysql metapackage for SLC4 - 3.1.0 PPS Update 10
#1541 glite-LFC_oracle metapackage for SLC4 - 3.1.0 PPS Update 10
#1370 R3.1/SLC4/i386 DPM/LFC 1.6.7-1 - 3.1.0 PPS Update 10"
Of course, some sites have been running SL3 DPM on SL4 for over a year and others have been running the development SL4 DPM in production for months. One warning I would give would be to make sure the information publishing is working, I've had a few problems with that in the past (in fact today I was battling with an incompatible version of perl-LDAP from the DAG repository).
06 December 2007
Storage as seen by SAM


We all need more monitoring, don't we? I knocked up these plots showing the storage SAM test results for the ops VO at GridPP sites over the past month. I am only looking at the SE and SRM tests here, where the result for each day is calculated as the number of successes over the total number of tests. The darker-green the square the higher the availability. I think it's clear which sites are having problems.
http://www.gridpp.ac.uk/wiki/GridPP_storage_available_monitoring
We always hear that storage is really unreliable for the experiments, so I was actually quite surprised at the amount of green on the first plot. However, I think since these results are only for the short duration ops tests, they do not truely reflect the view that the experiments have of storage when they are performing bulk data transfer across the WAN or a large amount of local access to the compute farm.
These plots were generated thanks to some great python scripts/tools from Brian Bockleman (and others, I think) from OSG. Brian's also got some interesting monitoring tools for dCache sites which I'm having a look at. It would be great if we could use something similar in GridPP.
04 December 2007
dCache 1.8.0-X
A new patch to dCache 1.8.0 was released on Friday (1.8.0-6). In addition, there is now a 1.8.0 dcap client. All rpms can be found here:
http://www.dcache.org/downloads/1.8.0/index.shtml
Sites (apart from Lancaster!) should wait for all of the Tier-1s to upgrade first of all as there are still some bugs being worked out.
http://www.dcache.org/downloads/1.8.0/index.shtml
Sites (apart from Lancaster!) should wait for all of the Tier-1s to upgrade first of all as there are still some bugs being worked out.
dCache admin scripts
 Last week I finally got a chance to have another look at some of the dCache administration scripts that are in the sysadmin wiki [1]. There is a jython interface to the dCache admin interface, but I find it difficult to use. As an alternative, the guys at IN2P3 have written a python module that creates a dCache admin door object which you can then use in your own python scripts to talk to the dCache [2]. One thing that I did was use the rc cleaner script [3] to clean up all of the requests (there were 100's!) that were stuck in Suspended state. You can see how the load on the machine running postgres dropped after removing the entries. Highly recommended.
Last week I finally got a chance to have another look at some of the dCache administration scripts that are in the sysadmin wiki [1]. There is a jython interface to the dCache admin interface, but I find it difficult to use. As an alternative, the guys at IN2P3 have written a python module that creates a dCache admin door object which you can then use in your own python scripts to talk to the dCache [2]. One thing that I did was use the rc cleaner script [3] to clean up all of the requests (there were 100's!) that were stuck in Suspended state. You can see how the load on the machine running postgres dropped after removing the entries. Highly recommended.I also wrote a little script to get information from the LoginBroker in order to print out how many doors are active in the dCache. This is essential information for sites that have many doors (i.e. Manchester) but find the dCache 2288 webpage difficult to use. I'll put it in the SVN repository soon.
[1] http://www.sysadmin.hep.ac.uk/wiki/DCache
[2] http://www.sysadmin.hep.ac.uk/wiki/DCache_python_interface
[3] http://www.sysadmin.hep.ac.uk/wiki/DCache_rc_cleaner
22 November 2007
gridpp-storage turns 1(00)
 Just thought I would let everyone know that we have now reached the 100th posting on this little blog and it also happens to fall exactly on the 1 year anniversary of it's creation. Strange how these two milestones coincide like that. Doing the maths, it means that there are about 2 postings per week. What I don't know, however, is whether or not this implies that there is too much or too little to talk about when it comes to Grid storage? Maybe it means I should be doing more work.
Just thought I would let everyone know that we have now reached the 100th posting on this little blog and it also happens to fall exactly on the 1 year anniversary of it's creation. Strange how these two milestones coincide like that. Doing the maths, it means that there are about 2 postings per week. What I don't know, however, is whether or not this implies that there is too much or too little to talk about when it comes to Grid storage? Maybe it means I should be doing more work.As an aside, when I said "everyone" above, I don't actually know how large "everyone" is. As a guess, I would say at most 7 people. Maybe a few comments below would prove me wrong...
Also, I should say that Lancaster are planning on moving to dCache 1.8.0 in production next week. This is great news as it measn they will be all set for the CCRC'08 (the last C means Challenge, that's the important bit) that is due to start 1Q08. Everyone else should have similar plans in their minds.
SRM2.2 deployment workshop - day 2 summary
OK, time to finish off my summary of the workshop; I'll try not to take as long this time.
After a great conference dinner (and amazing speech!) in the George Hotel, I made sure I was in NeSC early on the Wednesday morning to check everything was in working order after the power cut from the previous night. Unfortunately, there were a few gremlins in the system. First of all, a circuit breaker had gone, meaning that only half of the tutorial machines had power, and of those, only half of them had networking. At that point, the hands-on session was basically dead in the water. Fortunately, a University spark (that means electrician) appeared out of nowhere and flicked the switch. A quick reboot and all of the machines came back up - phew! I then had to spend a bit of time reconfiguring a few nodes which the developers had been set loose on; using virtual machines here would definitely have helped, but when I tried this prior to the workshop, the machines at NeSC were really struggling (I've already recommended that they upgrade their hardware). Anyway, the tutorials started and people were able to log on, configure some SRM2.2 spaces and run some client commands as a check. It helped to have the tutorial hand-out that I had prepared along with the dCache and DPM developers (thanks Timur + Sophie).
So far, so good, but disaster wasn't far away as the NeSC firewall had been reset overnight meaning that the tutorial machines could no longer speak to the top-level BDII in the physics department. This was discovered after a quick debug session from Grid guru Maarten Litmaath and the firewall rules were fixed. Unfortunately, this broke wireless connectivity for almost everyone in the building! By far, this was the worst thing that could happen at a Grid meeting - everyone was starting to foam at the mouth by lunch. To be honest, this was the best thing to happen as it meant there were no distractions from the tutorial - something to remember for next time I think ;)
The afternoon kicked off with a discussion about the the rigourous testing that the different SRM2.2 implementations have gone through to ensure they conform to the spec and are able to inter-operate. Things look good so far - fingers crossed in production it reamins the same. We then had a short sessiona about support as this is the latest big thing to talk about with regards to storage. The message that I would give to people is that make sure you stay involved in the community that we have built up; contribute to the mailing list (dpm-user-forum@cern.ch was announced!) and add to the wikis and related material that is on the web. It's really important that we help one another and not constantly pester the developers (although there help will still be needed!). The final session of the workshop talked about the SRM client tools and changes that have been made to them to support SRM2.2. Clearly, sites should have a good working relationship with these tools as they will be one of the mains weapons to check that SRM2.2 configuration is working as expected.
So that's it, the end of the SRM2.2 deployment workshop. I think everyone (well, most) enjoyed their time in Edinburgh and learnt a lot from each other. The hands-on proved a success and this should be noted for future events. Real data is (hopefully!) coming in 2008 so we had better make sure that the storage is prepared for it so that the elusive Higgs can be found! Remember, acting as a community is essential, so make sure that you stay involved!
See you next time.
After a great conference dinner (and amazing speech!) in the George Hotel, I made sure I was in NeSC early on the Wednesday morning to check everything was in working order after the power cut from the previous night. Unfortunately, there were a few gremlins in the system. First of all, a circuit breaker had gone, meaning that only half of the tutorial machines had power, and of those, only half of them had networking. At that point, the hands-on session was basically dead in the water. Fortunately, a University spark (that means electrician) appeared out of nowhere and flicked the switch. A quick reboot and all of the machines came back up - phew! I then had to spend a bit of time reconfiguring a few nodes which the developers had been set loose on; using virtual machines here would definitely have helped, but when I tried this prior to the workshop, the machines at NeSC were really struggling (I've already recommended that they upgrade their hardware). Anyway, the tutorials started and people were able to log on, configure some SRM2.2 spaces and run some client commands as a check. It helped to have the tutorial hand-out that I had prepared along with the dCache and DPM developers (thanks Timur + Sophie).
So far, so good, but disaster wasn't far away as the NeSC firewall had been reset overnight meaning that the tutorial machines could no longer speak to the top-level BDII in the physics department. This was discovered after a quick debug session from Grid guru Maarten Litmaath and the firewall rules were fixed. Unfortunately, this broke wireless connectivity for almost everyone in the building! By far, this was the worst thing that could happen at a Grid meeting - everyone was starting to foam at the mouth by lunch. To be honest, this was the best thing to happen as it meant there were no distractions from the tutorial - something to remember for next time I think ;)
The afternoon kicked off with a discussion about the the rigourous testing that the different SRM2.2 implementations have gone through to ensure they conform to the spec and are able to inter-operate. Things look good so far - fingers crossed in production it reamins the same. We then had a short sessiona about support as this is the latest big thing to talk about with regards to storage. The message that I would give to people is that make sure you stay involved in the community that we have built up; contribute to the mailing list (dpm-user-forum@cern.ch was announced!) and add to the wikis and related material that is on the web. It's really important that we help one another and not constantly pester the developers (although there help will still be needed!). The final session of the workshop talked about the SRM client tools and changes that have been made to them to support SRM2.2. Clearly, sites should have a good working relationship with these tools as they will be one of the mains weapons to check that SRM2.2 configuration is working as expected.
So that's it, the end of the SRM2.2 deployment workshop. I think everyone (well, most) enjoyed their time in Edinburgh and learnt a lot from each other. The hands-on proved a success and this should be noted for future events. Real data is (hopefully!) coming in 2008 so we had better make sure that the storage is prepared for it so that the elusive Higgs can be found! Remember, acting as a community is essential, so make sure that you stay involved!
See you next time.
17 November 2007
SRM2.2 deployment workshop - day 1 summary
So that's the workshop over - it really flew by after all of the preparation that was required to set things up! Thanks to everyone at NeSC for their help with the organisation and operations on the day. Thanks also to everyone who gave presentations and took tutorials at the workshop, I think these really allowed people to learn about SRM2.2 and all of the details required to configure DPM, dCache or StoRM storage at their site.
Day 1 started with parallel dCache Tier-1 and StoRM sessions. It was particularly good for the StoRM developers to get together with interested sites as they haven't had much of a chance to do this before. For dCache (once the main developer arrived!), FZK and NDGF were able to pass on information to the developers and other Tier-1s about performing the upgrade to v1.8.0. It was noted that NDGF are currently just using 1.8.0 as a drop in replacement for 1.7.0 - space management has yet to be turned on. FZK had experienced a few more problems - primarily due to a high load on PNFS. However, the eventual cause was traced to a change in pool names without a subsequent re-registration - this is unrelated to 1.8.0.
I had arranged for lunch for the people who turned up in the morning. Of course, I should have known that a few extras would have turned up - but I didn't expect quite as many. Luckily we had enough food, just. I'll know better for next time!
The main workshop started in the afternoon where the concepts of SRM2.2 were presented in order to educate sites and give them the language that would be used during the rest of the workshop. Thanks to Flavia Donno and Maarten Litmaath describing the current status. We then moved onto short presentations from each of the storage developers, outlining the system and how SRM2.2 was implemented. Again, this helped to explain concepts to sites and enabled them to see the differences with the software that is currently deployed.
Stephen Burke gave a detailed presentation about v1.3 of the GLUE schema. This is important as it was introduced to allow for SRM2.2 specific information to be published in the information system. Sites need to be aware of what their SEs should be publishing - there should be a SAM test that will check this out.
The final session of the day was titled "What do experiments want from your storage?". I was hoping that we could get a real idea of how ATLAS, CMS and LHCb would want to use SRM2.2 at the sites, particularly Tier-2s. LHCb appear to have the clearest plan of what they want to do (although they don't want to use Tier-2 disk) as they were presenting exactly the data types and space tokens that they would like set up. CMS presented gave a variety of ideas for how they could use SRM2.2 to help with the data management. While these are not finalised I think they should form the basis for further discussion between all interested parties. For ATLAS, Graeme Stewart gave another good talk about their computing model and data management. Unfortunately, it was clear that ATLAS don't really have a plan for SRM2.2 at Tier-1s or 2s. He talked about ATLAS_TAPE and ATLAS_DISK space tokens, which is a start, but what is the difference between this and just having separate paths (atlas/disk and atlas/tape) in the SRM namespace? What was clear, however, was that ATLAS (and the other experiments) want storage to be available, accessible and reliable. This is essential for both WAN data transfers and local access for compute jobs and is really what the storage community have to focus on prior to the start of data taking - we are here for the physics after all!
So, Day 1 went well, that is until we had a power cut just after the final talk! To be honest though, it turned out to be a good thing as it meant people stopped working on their laptops and got out to the pub. This was another reason for having the workshop - allowing people to mix and match faces to the names that they have seen on the mailing lists. It all helps to foster that community spirit that we need to support each other,
OK, enough for now. I'll talk about Day 2 later.
Day 1 started with parallel dCache Tier-1 and StoRM sessions. It was particularly good for the StoRM developers to get together with interested sites as they haven't had much of a chance to do this before. For dCache (once the main developer arrived!), FZK and NDGF were able to pass on information to the developers and other Tier-1s about performing the upgrade to v1.8.0. It was noted that NDGF are currently just using 1.8.0 as a drop in replacement for 1.7.0 - space management has yet to be turned on. FZK had experienced a few more problems - primarily due to a high load on PNFS. However, the eventual cause was traced to a change in pool names without a subsequent re-registration - this is unrelated to 1.8.0.
I had arranged for lunch for the people who turned up in the morning. Of course, I should have known that a few extras would have turned up - but I didn't expect quite as many. Luckily we had enough food, just. I'll know better for next time!
The main workshop started in the afternoon where the concepts of SRM2.2 were presented in order to educate sites and give them the language that would be used during the rest of the workshop. Thanks to Flavia Donno and Maarten Litmaath describing the current status. We then moved onto short presentations from each of the storage developers, outlining the system and how SRM2.2 was implemented. Again, this helped to explain concepts to sites and enabled them to see the differences with the software that is currently deployed.
Stephen Burke gave a detailed presentation about v1.3 of the GLUE schema. This is important as it was introduced to allow for SRM2.2 specific information to be published in the information system. Sites need to be aware of what their SEs should be publishing - there should be a SAM test that will check this out.
The final session of the day was titled "What do experiments want from your storage?". I was hoping that we could get a real idea of how ATLAS, CMS and LHCb would want to use SRM2.2 at the sites, particularly Tier-2s. LHCb appear to have the clearest plan of what they want to do (although they don't want to use Tier-2 disk) as they were presenting exactly the data types and space tokens that they would like set up. CMS presented gave a variety of ideas for how they could use SRM2.2 to help with the data management. While these are not finalised I think they should form the basis for further discussion between all interested parties. For ATLAS, Graeme Stewart gave another good talk about their computing model and data management. Unfortunately, it was clear that ATLAS don't really have a plan for SRM2.2 at Tier-1s or 2s. He talked about ATLAS_TAPE and ATLAS_DISK space tokens, which is a start, but what is the difference between this and just having separate paths (atlas/disk and atlas/tape) in the SRM namespace? What was clear, however, was that ATLAS (and the other experiments) want storage to be available, accessible and reliable. This is essential for both WAN data transfers and local access for compute jobs and is really what the storage community have to focus on prior to the start of data taking - we are here for the physics after all!
So, Day 1 went well, that is until we had a power cut just after the final talk! To be honest though, it turned out to be a good thing as it meant people stopped working on their laptops and got out to the pub. This was another reason for having the workshop - allowing people to mix and match faces to the names that they have seen on the mailing lists. It all helps to foster that community spirit that we need to support each other,
OK, enough for now. I'll talk about Day 2 later.
SRM2.2 deployment workshop - picture gallery





If people have any more photos that they would like to share, then feel free to send them to me.
16 November 2007
Storage workshops - the solution to (most of) our problems

While reviewing the outcomes of the workshop, I have come to the conclusion that we should have storage workshops more often as they clearly improve the reliability and availability of Grid storage. I took this snapshot of SAM test results for UK sites the day after the Edinburgh meeting and I think it's obvious that there is a lot of green about, although one site shall remain nameless...
Unfortunately, normal service appears to have resumed. So who is planning the next meeting?
14 November 2007
Dark storage?
The lights went out on the SRM2.2 deployment workshop yesterday evening, but it was timed to perfection as the final talk had just finished! Clearly my plan to get everyone out of the building worked really well ;)
Dinner in the George Hotel was excellent (as was the beer afterwards), I will post some photos from the restaurant and day-1 at some point today.
Dinner in the George Hotel was excellent (as was the beer afterwards), I will post some photos from the restaurant and day-1 at some point today.
10 November 2007
SRM2.2 deployment workshop - bulletin 5
View Larger Map
The workshop is almost upon us, I can't believe it's come round this fast! It was only a few weeks ago that I was proposing the idea of running this event. Preparations have been continuing apace and I now have the computer lab set up with 20 dCache and DPM test instances. Interested participants will use their laptops to connect to these machines during the tutorials and will configure the SRM2.2 service. There will be contributions from many sources during the workshop; the developers, experiment representatives and members of the WLCG GSSD are all putting together material. Thanks to everyone for all of their efforts!
The map above pinpoints some of the main locations that you will need to know about during the workshop. Hopefully you'll get the chance to see some more of Edinburgh's attractions while you are here.
Check Indico for the latest agenda:
http://indico.cern.ch/conferenceDisplay.py?confId=21405
Note that we have added a discussion session about the future of storage support. This is important given that (fingers crossed) we will be receiving physics data next year; we need to ensure the storage services have high availability and reliability.
See you next week.
02 November 2007
SRM2.2 deployment workshop - bulletin 4
 We are now up to 55 registered participants! This is great - clearly a lot of people are interested in learning about SRM and the workshop presents a good opportunity for everyone to meet the middleware developers; find out about basics (and the complexities) of SRM2.2 and exchange hints/tips with site admins from all over WLCG.
We are now up to 55 registered participants! This is great - clearly a lot of people are interested in learning about SRM and the workshop presents a good opportunity for everyone to meet the middleware developers; find out about basics (and the complexities) of SRM2.2 and exchange hints/tips with site admins from all over WLCG.I would ask everyone to come prepared for the workshop - have a think about your current storage setup and how this will be changing over the coming year. I would imagine everyone will be buying more disk so how do you want this set up? If you support many VOs, do you want to give dedicated disk to some of them while the others share?
Also, I've worked out some more of the technicalities of the hands on session. There are 20 desktop machines at NeSC which we can use for the tutorial and I have started setting up dCache/DPM images which will be rolled out across the cluster. I'll ask everyone to use their laptops to ssh onto the machines, but everyone will have to work in pairs; unfortunately there aren't hosts for one each. We'll be using a temporary CA for host and user certificates.
Finally, just to clarify that the workshop starts at 1pm on Tuesday 13th Nov. Make sure you pick up some lunch beforehand! You should be able to find plenty of eateries near to NeSC. Looking forward to see you all soon.
http://indico.cern.ch/conferenceDisplay.py?confId=21405
25 October 2007
SRM2.2 deployment workshop - bulletin 3
 Just thought I would give a quick update as to the organisation of the workshop. First of all, thanks to those who have already registered - we are fast approaching our limit and the registration page will be closed soon (so apply now if you still would like to come).
Just thought I would give a quick update as to the organisation of the workshop. First of all, thanks to those who have already registered - we are fast approaching our limit and the registration page will be closed soon (so apply now if you still would like to come).http://www.nesc.ac.uk/esi/events/827/
Secondly, I have changed the format of the Indico agenda page to use the "conference" format. Hopefully this makes more sense since we are having a couple of parallel sessions during the workshop which was difficult to see from the default layout.
Thirdly, I am working with people at NeSC to try and setup a hands on session where delegates get a chance to "play" with the SRM2.2 configuration on a dCache or DPM. At the moment there are still some technical "challenges" to overcome. I'll keep you posted.
As always, get in touch if there are any questions.
PS Can anyone name the tartan?
16 October 2007
SRM2.2 deployment workshop - bulletin 2

The registration page for the workshop is now available.
http://www.nesc.ac.uk/esi/events/827/
Could everyone who has pre-registered their interest to me please complete the registration form. If you require accommodation you should select the relevant nights and this will be booked for you by NeSC (they will not be paying for it though!). I have a list of names of those who have pre-registered, so I'll be chasing up anyone who does not fill out the form.
The agenda can be found here:
http://indico.cern.ch/conferenceDisplay.py?confId=21405
If you have any SRM or storage issues that you would like raised at the workshop, please let me know and I will try to ensure that it is covered at some stage.
Looking forward to seeing you in Edinburgh!
12 October 2007
OSG storage group
I was in a meeting yesterday with the OSG data storage and management group. I had realised that there was some activity going on in the US regarding this, but didn't know just how many people are involved, or what precisely they were doing. Turns out that there is actually quite a few FTEs looking at dCache 1.8 testing, client tools, deployment scripts, bug reports and support. There is clearly quite an overlap with what we try to do in GridPP, although there are a couple of differences:
1. GridPP has only me (and part of Jens) dedicated to storage. The rest comes from the community of site admins that have signed up to the mailing list. This works well, but it would be good if there were others who could dedicate more time to looking at storage issues. There were previously a couple of positions at RAL for this stuff. Hopefully there will be again in GridPP3.
2. Unlike GridPP, OSG is not dedicated to particle physics, hence they support other user communities. It appears that USATLAS and USCMS take on the lions share of support for storage at US Tier-2 sites.
You can find more information here:
https://twiki.grid.iu.edu/twiki/bin/view/Storage/
1. GridPP has only me (and part of Jens) dedicated to storage. The rest comes from the community of site admins that have signed up to the mailing list. This works well, but it would be good if there were others who could dedicate more time to looking at storage issues. There were previously a couple of positions at RAL for this stuff. Hopefully there will be again in GridPP3.
2. Unlike GridPP, OSG is not dedicated to particle physics, hence they support other user communities. It appears that USATLAS and USCMS take on the lions share of support for storage at US Tier-2 sites.
You can find more information here:
https://twiki.grid.iu.edu/twiki/bin/view/Storage/
06 October 2007
Interview with ZFS techies - mentions LHC
These guys (Jeff Bonwick and Bill Moore) are techies so not a sales pitch at all. Running time about 48 mins but you can do something else and just listen to it (like in a meeting :-)
http://www.podtech.net/scobleshow/technology/1619/talking-storage-systems-with-suns-zfs-team
Suitable for everyone, covers a lot of software engineering ("software is only as good as its test suite") but also obviously filesystems and "zee eff ess" and storage.
Also mentions CERN's LHC, and the LHC Atlas detector in particular.
And work done by CERN to examine silent data corruption (at around 33 mins into the interview).
http://www.podtech.net/scobleshow/technology/1619/talking-storage-systems-with-suns-zfs-team
Suitable for everyone, covers a lot of software engineering ("software is only as good as its test suite") but also obviously filesystems and "zee eff ess" and storage.
Also mentions CERN's LHC, and the LHC Atlas detector in particular.
And work done by CERN to examine silent data corruption (at around 33 mins into the interview).
01 October 2007
SRM2.2 deployment workshop - bulletin 1
 This is the first bulletin for the "SRM2.2 Deployment Workshop" which will take place on Tuesday the 13th and Wednesday the 14th of November 2007. The workshop is being organised by the UK's National eScience Centre (NeSC), GridPP and WLCG. It will take place at NeSC, Edinburgh, Scotland.
This is the first bulletin for the "SRM2.2 Deployment Workshop" which will take place on Tuesday the 13th and Wednesday the 14th of November 2007. The workshop is being organised by the UK's National eScience Centre (NeSC), GridPP and WLCG. It will take place at NeSC, Edinburgh, Scotland.The goal of the workshop is to bring WLCG site administrators with experience of operating dCache and DPM storage middleware together with the core developers and other Grid storage experts. This will present a forum for information exchange regarding the deployment and operation of
SRM2.2 services on the WLCG. By the end of the workshop, site administrators will be fully aware of the technology that must be deployed in order to provide a service that fully meets the needs of the LHC physics programme.
Particular attention will be paid to the large number of sites who contribute small amounts of computing and storage resource (Tier-2s), as compared with national laboratories (Tier-1s). Configuration of SRM2.2 spaces and storage information publishing will be the main topics of
interest during the workshop. In addition, there will be a dedicated session for the Tier-1 sites running dCache.
As SRM2.2 has been proposed as an Open Grid Forum (OGF) standard, it is likely that the workshop will be of wider interest than only WLCG. However, it should be noted that the intention of the meeting is not to continue discussions of the current specification or of any future
version. The meeting will focus on the deployment of a production system.
It is intended that the meeting will be by invitation only. Anyone who thinks that they should receive an invitation should contact Greig Cowan to register their interest.
A detailed agenda and general information about the event are currently being prepared. A second announcement will be made once these are in place.
Subscribe to:
Posts (Atom)

