Hello, my full name is data10_7TeV.%$%$%$%$%.RAW but you can call me Dave. I am a dataset within ATLAS. Here I will be blogging my history and that of all the dataset replicas and children datasets that the physicists produce from me.
I came about from data taking at the LHC on the 30th March 2010 from the ATLAS detector.
I initially have 1779 files containing 675757 events. I was born a good 3.13TB
By the end of my first day I have already been copied so that I exist in two copies on disk and two sets of tape. This should result on my continual survival so as to avoid loss.
So I am now secure in my own existance; lets see if any one care to read me or move to different sites.
31 March 2010
30 March 2010
Analysing a node chock full of analysis.
As Wahid's previous post notes, we've been doing some testing and benchmarking of the performance of data access under various hardware and data constraints (particularly: SSDs vs HDDs for local storage, "reordered" AODs vs "unordered" AODs, and there are more dimensions to be added).
 Node 300 (above)
Node 300 (above)
 Node 305 (above)
Node 305 (above)
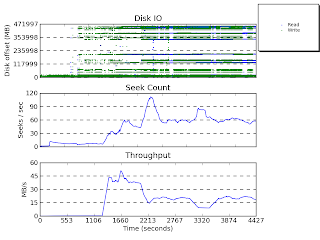

Although this is a little preliminary, I took some blktrace traces of the activity on a node with an SSD (an Intel X25 G2) mounted on /tmp, and a node with a standard partition of the system HDD as /tmp, whilst they coped with being filled full of HammerCloud-delivered muon analysis jobs. Each trace was a little over an hour of activity, starting with each HammerCloud test's start time.
Using seekwatcher, you can get a quick summary plot of the activity of the filesystem during the trace.
In the following plots, node300 is the one with the HDD, and node305 is the one with the SDD.
Firstly, under stress from analysis of the old AODs, not reordered:
 Node 300 (above)
Node 300 (above) Node 305 (above)
Node 305 (above) As you can see, the seek rates for the HDD node hit the maximum expected seeks per second for a 7200 rpm device (around 120 seeks per second), whilst the seeks on the SSD peak at around 2 to 2.5 times that. The HDD's seek rate is a significant limit on the efficiency of jobs under this kind of load.
Now, for the same analysis, against reordered AODs. Again, node300 first, then node305.


Notice that the seek rate for both the SSD and the HDD peak below 120 seeks per second, and the sustained seek rate for both of them is around half that. (This is with both nodes loaded completely with analysis work).
So, reordering your datasets definitely improves their performance with regard to seek ordering...
So, reordering your datasets definitely improves their performance with regard to seek ordering...
26 March 2010
Testing times
Data analysis at grid sites is hard on poor disk servers. This is part because of the "random" access pattern seen on accessing jobs. Recently LHC experiments have been "reordering" their files to match more the way they might be expected to be accessed.
Initially the access pattern on these new files looks more promising as these plots showed.
But those tests read the data in the new order so are sure to see improvements. Also, as the plots hint at, any improvement is very dependent on access method, file size, network config and a host of other factors.
So recently we have been trying accessing these datasets with real ATLAS analysis type jobs at Glasgow. Initial indications look like the improvement will not be quite as much as hoped but tests are ongoing so we'll report back.
Initially the access pattern on these new files looks more promising as these plots showed.
But those tests read the data in the new order so are sure to see improvements. Also, as the plots hint at, any improvement is very dependent on access method, file size, network config and a host of other factors.
So recently we have been trying accessing these datasets with real ATLAS analysis type jobs at Glasgow. Initial indications look like the improvement will not be quite as much as hoped but tests are ongoing so we'll report back.
04 March 2010
Checksumming and Integrity: The Challenge
One key focus of the Storage group as whole at the moment is the thorny issue of data integrity and consistency across the Grid. This turns out to be a somewhat complicated, multifaceted problem (the full breakdown is on the wiki here), and one which already has fractions of it solved by some of the VOs.
ATLAS, for example, has some scripts managed by Cedric Serfon which do the checking of data catalogue consistency correctly, between ATLAS's DDM system, the LFC and the local site SE. They don't, however, do file checksum checks, and therefore there is potential for files to be correctly placed, but corrupt (although this would be detected by ATLAS jobs when they run against the file, since they do perform checksums on transferred files before using them).
The Storage group has an integrity checker which does checksum and catalogue consistency checks between LFC and the local SE (in fact, it can be run remotely against any DPM), but it's much slower than the ATLAS code (mainly because of the checksums).
Currently, the plan is to split effort between improving VO specific scripts (adding checksums), and enhancing our own script - one issue of key importance is that the big VOs will always be able to write specific scripts for their own data management infrastructures than we will, but the small VOs deserve help too (perhaps more so than the big ones), and all these tools need to be interoperable. One aspect of this that we'll be talking about a little more in a future blog post is standardisation of input and output formats - we're planning on standardising on SynCat, or a slightly-derived version of SynCat, as a dump and input specifier format.
This post exists primarily as an informational post, to let people know what's going on. More detail will follow in later blog entries. If anyone wants to volunteer their SE to be checked, however, we're always interested...
01 March 2010
A Phew Good Files
The storage support guys finished integrity checking of 5K ATLAS files held at Lancaster and found no bad files.
This, of course, is a Good Thing™.
The next step is to check more files, and to figure out how implementations cache checksums. Er, the next two steps are to check more files and document handling checksums, and do it for more experiments. Errr, the next three steps are to check more files, document checksum handling, add more experiments, and integrate toolkits more with experiments and data management tools.
There have been some reports of corrupted files but corruptions can happen for more than one reason, and the problem is not always at the site. The Storage Inquisition investigation is ongoing.
This, of course, is a Good Thing™.
The next step is to check more files, and to figure out how implementations cache checksums. Er, the next two steps are to check more files and document handling checksums, and do it for more experiments. Errr, the next three steps are to check more files, document checksum handling, add more experiments, and integrate toolkits more with experiments and data management tools.
There have been some reports of corrupted files but corruptions can happen for more than one reason, and the problem is not always at the site. The Storage Inquisition investigation is ongoing.
Subscribe to:
Comments (Atom)

