With a 1.5PB Lustre file system set up we now need to transfer our data from the old lustre system, conveniently also 1.5 PB in size, before we can put it into production.
Migration of Data:
It was found that is was not possible to mount both Lustre 1.8 and 2.8 on the same client, therefore migration of data had to be done via rsync between two clients mounting the different Lustre file systems. Setting up an rsync demon on the clients was found to be an order of magnitude quicker than using rsync over ssh for transferring data between the two clients. Hard links, ACLs and extended attributes are preserved by using the “-HAX” option when transferring data. Up to a dozen clients were utilised over the course of about six weeks to transfer 1.5PB of data between the old and new Lustre file systems. After the initial transfer the old and new systems were kept in sync with repeated rsync runs, remembering to use the “—delete” option to remove files that no longer existed on the live Lustre system. MD5 checksums were compared for a small random selection of files. The final transfer from the old to new Lustre took about a day, during which the file system was unavailable to external users. Then all clients were updated to the new Lustre version.
Real World Experience:
With the new Lustre system put into production we then recommissioned the old system to create a 3PB Lustre file system. The grid cluster has about 4000 job slots in over 200 Lustre client compute nodes. The actual cluster is shown below. Note that the compute nodes fill the bottom 12U of every rack, where the air is cooler, and storage above them in the next 24U.

Real world performance over half a year, March to September 2016, is shown below. When all job slots are running grid “analysis” workloads, requiring access to data stored in Lustre, no slow down in job efficiency was observed. An average of 4.8 Gb/s is seen for reading data from Lustre and 1.6Gb/s for writing to Lustre (which is always done through StoRM).

However, in one case a local user simultaneously ran more than a 1500 jobs each accessing a very large number of small files, in this case BIOinformatics data, on Lustre and a slow down in performance was observed. Once the user was limited to no more than 500 jobs no further issues were seen. It is expected that accessing small files on the Lustre filesystem is not efficient [1] and should be avoided or limited where possible. A future enhancement to Lustre is planned that will enable small files to be stored on the MDS which should improve small file performance [1].
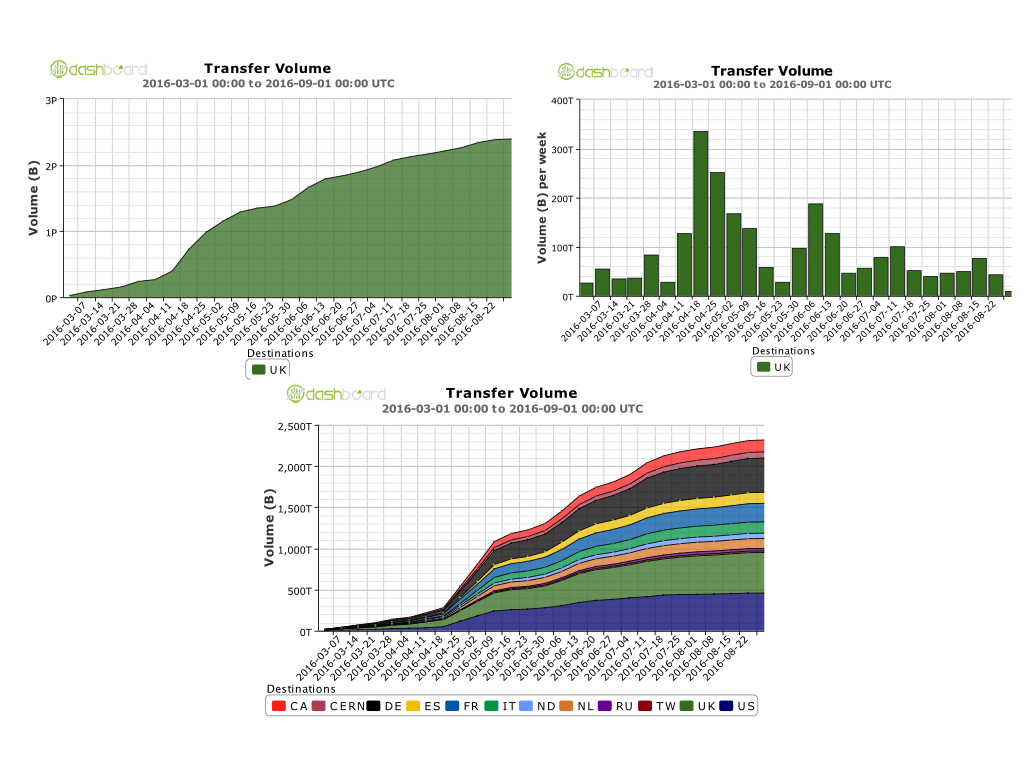
The Queen Mary Grid site major workload is for the ATLAS experiment which keeps detailed statistics of site usage. We are responsible for processing about 2.5% of all ATLAS data internationally and about 20% of data processed in the UK. Remote data transfer statics are shown below. Over the last 6 months ATLAS has transferred 2.39 PB of data into the cluster (top left plot), the weekly totals are shown in the top left plot, with a maxim for one week of 340TB (an average 4Gb/s). The bottom plot shows that 2.3PB has been sent to other grid sites around the world from Queen Mary.
Future Plans:
- Double the Storage of the cluster to 6PB in 2018.
- Consider an upgrade to Lustre 2.9 which will have bug LU1482 fixed and also provide additional functionality such as user and group ID mapping which would allow the storage to be used in different clusters. However Lustre 2.9 is SL/Centos7 only.
- Upgrade OSS servers to SL/CentOS 7 from SL6.
- Examine the use of ZFS in place of hardware raid which might help mitigate very long raid rebuild times after replacement of a failed hard drive.
Conclusions:
Over the past 4 Blogs we have shown a successful major upgrade of Lustre. Including the specification, installation, configuration, migration of data, and operation of hardware and software.


No comments:
Post a Comment